Часть 3. Обработка данных статистических наблюдений")





: Разделение всей совокупности на качественно однородные группы – типологические группировки; Характеристика структуры яв…")

")











 – для изображения дискретных вариационных рядов (табл.8).")
.")
 – для изображения вариационных рядов (табл.9). Разница только в расположении осей.")




 различной формы.")
2)1/2 k=1 dij - расстояние между объектами Xik - численное значение i-о…")



![Рассчитываем расстояния между объектами*: d = [ (2 – 4)2 + (8 – 10)2 ]1/2 = 81/2 = 2,83 d = [ (2 – 5)2 + (8 – 7)2 ]1/2 = 101/2 = 3,16 d = [ (2 – 12)2 + (8 – 6)2 ]1/2 = 1041/2 = 10,2 d = [ (2 – 14)2 + (8 – 6)2 ]1/2 = 1481/2 = 12,16 d = [ (2 – 15)2 + …](https://fs1.ppt4web.ru/images/95289/117487/640/img35.jpg "Рассчитываем расстояния между объектами*: d = [ (2 – 4)2 + (8 – 10)2 ]1/2 = 81/2 = 2,83 d = [ (2 – 5)2 + (8 – 7)2 ]1/2 = 101/2 = 3,16 d = [ (2 – 12)2 + (8 – 6)2 ]1/2 = 1041/2 = 10,2 d = [ (2 – 14)2 + (8 – 6)2 ]1/2 = 1481/2 = 12,16 d = [ (2 – 15)2 + …")

, которые объединяются в группу, в новой матрице эта группа представлена отдельной позицией 4-5 с расстояниями,…")



Презентация на тему: Обработка данных статистических наблюдений
 Часть 3. Обработка данных статистических наблюд")
СТАТИСТИКА I (теория статистики) Часть 3. Обработка данных статистических наблюдений

Обработка данных статистических наблюдений включает: Статистическую сводку; Группировку; Ряды распределения; Кластерный анализ.

3.1 Статистическая сводка

3.2 Группировка

3.2 Группировка

3.2 Группировка

3.2 Группировка Метод группировки позволяет решить три задачи (разграничение условное, одна группировка может решить все задачи): Разделение всей совокупности на качественно однородные группы – типологические группировки; Характеристика структуры явления и структурных сдвигов – структурные группировки; Изучение взаимосвязей между отдельными признаками изучаемого явления – аналитические группировки.

Таблица 1. Типологическая группировка Группировка полиграфических предприятий одного из городов по формам собственности

Таблица 2. Структурная группировка Группировка населения России по размеру среднедушевого дохода (условные цифры)

Таблица 3. Аналитическая группировка Группировка продолжительности договорных связей книжного магазина и качества продукции

3.2 Группировка

Методы определения числа групп, интервалов группировок После определения основания группировки следует решить вопрос о количестве групп, на которые надо разбить исследуемую совокупность. Число групп зависит от задач исследования, численности совокупности, степени вариации признака. После определения числа групп следует определить интервалы группировки. Интервал – это значения варьирующего признака, лежащие в определённых границах. Нижней границей интервала называется наименьшее значение признака в интервале, а верхней границей – наибольшее значение признака в нём. Величина (ширина) интервала представляет собой разность между верхней и нижней границами интервала.

Таблица 4. Простая статистическая таблица Данные по з/п водителей за сентябрь

Таблица 5. Групповая статистическая таблица Данные по з/п водителей за сентябрь в зависимости от категории и процента выполнения задания

Таблица 6. Комбинационная статистическая таблица Зависимость з\п водителей от квалификации и процента выполнения задания

При составлении таблиц необходимо соблюдать общие правила: При составлении таблиц необходимо соблюдать общие правила: таблица должна быть легко обозримой; общий заголовок должен кратко выражать основное содержание; наличие строк «общих итогов»; наличие нумерации строк, которые заполняются данными; соблюдение правила округления чисел.

3.3 Ряды распределения

Таблица 7. Атрибутивный ряд распределения Распределение строительных организаций РФ по формам собственности

Таблица 8. Дискретный вариационный ряд Распределение рабочих предприятия по тарифному разряду

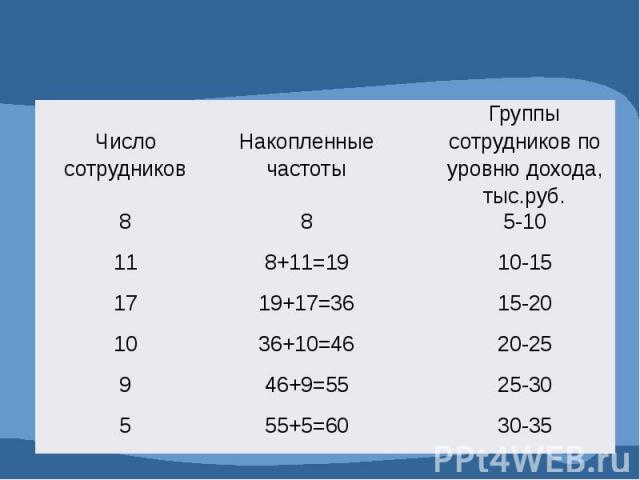
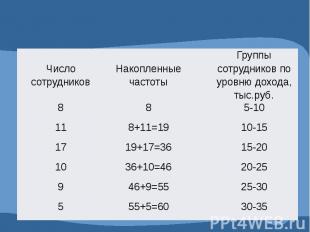
Таблица 9. Интервальный вариационный ряд Распределение сотрудников по уровню доходов
 – для изображения")
1.ПОЛИГОН распределения (разновидность статистических ломаных) – для изображения дискретных вариационных рядов (табл.8).
")
2. ГИСТОГРАММА частот – для изображения интервальных вариационных рядов (табл.9).
 – для изображения вариационных рядов (табл.9). Разница тольк")
3. КУМУЛЯТА (ОГИВА) – для изображения вариационных рядов (табл.9). Разница только в расположении осей.

ОГИВА

3.4 Кластерный анализ cluster – означает скопление, группу элементов, обладающих общими свойствами. Кластерный анализ — это совокупность методов, позволяющих классифицировать многомерные наблюдения, каждое из которых описывается набором исходных переменных Х1, Х2, ..., Хm. Целью кластерного анализа является образование групп схожих между собой объектов. В отличие от комбинационных группировок кластерный анализ приводит к разбиению на группы с учетом всех групировочных признаков одновременно.

Кластеризация – это процесс разбиения множества объектов на кластеры. Слева изображены объекты до кластеризации, а справа – после. Каждый кластер имеет свой цвет.

Критерий кластеризации в той или иной мере отражает следующие неформальные требования: Критерий кластеризации в той или иной мере отражает следующие неформальные требования: • внутри групп объекты должны быть похожи близки друг к другу; • объекты разных групп должны быть далеки друг от друга; • при прочих равных условиях распределения объектов по группам должны быть равномерными.

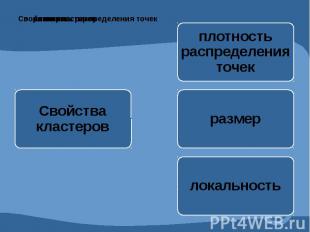
Кластер – это множество объектов, близких между собой по некоторой мере сходства. В пространстве переменных кластеры представляют собой скопления точек (объектов) различной формы.
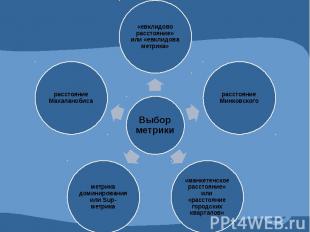

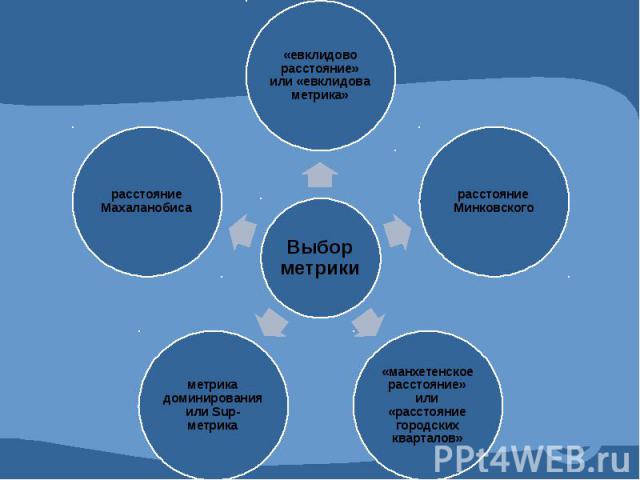
Наиболее доступно для восприятия и понимания в случае количественных признаков так называемое «евклидово расстояние» или «евклидова метрика». m dij = (Σ (Xik – Xjk)2)1/2 k=1 dij - расстояние между объектами Xik - численное значение i-ой переменной для k-того объекта Xjk - численное значение j-ой переменной для k-того объекта m – количество переменных, которыми описываются объекты *Если имеется два количественных признака, то искомое расстояние будет равно длине гипотенузы прямоугольного треугольника, которая соединяет между собой две точки в прямоугольной системе координат.

правила объединения или связи

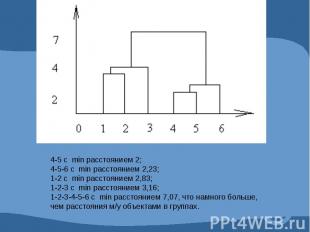
Дендрограмма – графическое изображение результатов процесса последовательной кластеризации, которая осуществляется в терминах матрицы расстояний. С помощью дендрограммы можно графически или геометрически изобразить процедуру кластеризации при условии, что эта процедура оперирует только с элементами матрицы расстояний или сходства.

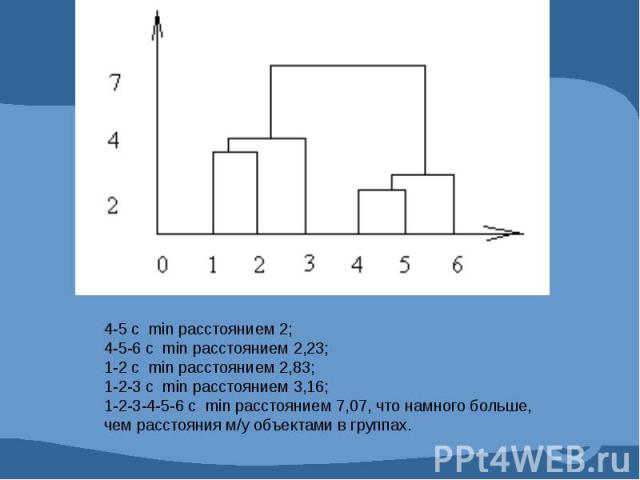
Пример для двух переменных и шести наблюдений.
![Рассчитываем расстояния между объектами*: d = [ (2 – 4)2 + (8 – 10)2 ]1/2 = 81/2](https://fs1.ppt4web.ru/images/95289/117487/310/img35.jpg "Рассчитываем расстояния между объектами*: d = [ (2 – 4)2 + (8 – 10)2 ]1/2 = 81/2")
Рассчитываем расстояния между объектами*: d = [ (2 – 4)2 + (8 – 10)2 ]1/2 = 81/2 = 2,83 d = [ (2 – 5)2 + (8 – 7)2 ]1/2 = 101/2 = 3,16 d = [ (2 – 12)2 + (8 – 6)2 ]1/2 = 1041/2 = 10,2 d = [ (2 – 14)2 + (8 – 6)2 ]1/2 = 1481/2 = 12,16 d = [ (2 – 15)2 + (8 – 4)2 ]1/2 = 1851/2 = 13,6 d = [ (4 – 5)2 + (10 – 7)2 ]1/2 = 101/2 = 3,16 d = [ (4 – 12)2 + (10 – 6)2 ]1/2 = 801/2 = 8,94 d = [ (4 – 14)2 + (10 – 6)2 ]1/2 = 1161/2 = 10,77 d = [ (4 – 15)2 + (10 – 4)2 ]1/2 = 1571/2 = 12,53 d = [ (5 – 12)2 + (7 – 6)2 ]1/2 = 501/2 = 7,07 d = [ (5 – 14)2 + (7 – 6)2 ]1/2 = 821/2 = 9,05 d = [ (5 – 15)2 + (7 – 4)2 ]1/2 = 1091/2 = 10,44 d = [ (12 – 14)2 + (6 – 6)2 ]1/2 = 41/2 = 2 d = [ (12 – 15)2 + (6 – 4)2 ]1/2 = 131/2 = 3,6 d = [ (14 – 15)2 + (6 – 4)2 ]1/2 = 51/2 = 2,23

Матрица расстояний:

Определяем пару объектов, расположенных наиболее близко друг к другу (в наше примере это объекты 4 и 5, расстояние между которыми равно 2), которые объединяются в группу, в новой матрице эта группа представлена отдельной позицией 4-5 с расстояниями, равными минимальным расстояниям 4 и 5 объекта до соседей.

Далее процедура повторяется: к 4 и 5 объектам добавляется объект 6 и возникает новая матрица.

Далее, ближайшее расстояние между 1 и 2 объектами, появляется новая группа 1-2.

Далее объект 3 присоединяется к группе 1-2, как к ближайшей.