


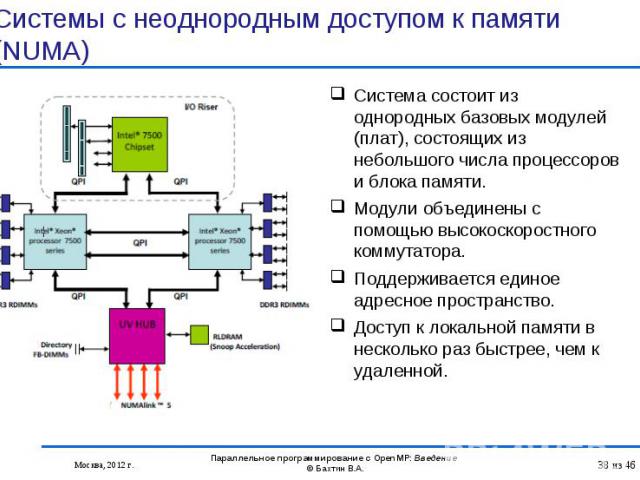
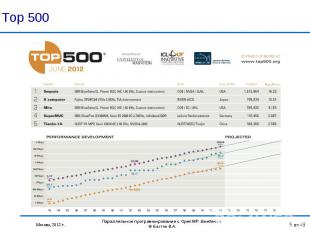
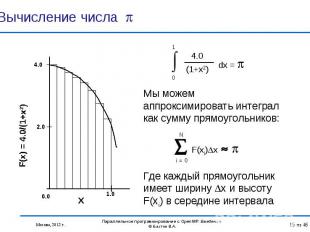
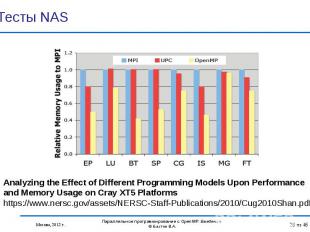
. В течение н…")






 1,73 ГГц Intel Itanium 9350 (Tukwila) 1,73 ГГц 4 ядeр 8 потоков с технологией Intel Hyper-Threading 24 МБ L3 кэш-памяти технология Intel QuickPath Interconnect технология Intel Turbo Boost")




: (col. 5) remark: LOOP WAS AUTO-PARALLELIZED. pi.c(8): (col. 5) remark: LOOP WAS VECTORIZE…")
, CAPTools/ParaWise, BERT77, FORGE Magic/DM, ДВОР (Диалоговый Высокоуровневый Оптимизирующий Распараллеливатель), САПФОР (Система Автоматизации Параллелизации ФОРтран программ) Intel/GAP (Guided Auto-Parallel), CAPToo…")
: remark #30521: (PAR) Loop at line 49 cannot be parallelized due to conditional assignment(s) into the following variable(s): b. This loop will be parallelized if the variable(s) become unconditionally initialized at the top of every it…")









 OpenMP 3.0: PGI 8.0: Linux and Windows IBM 10.1: Linux and AIX Cray: Cray XT series Linux environment Absoft Pro FortranMP: 11.…")










Презентация на тему: Учебный курс Параллельное программирование с OpenMP



В течение нескольких десятилетий развитие ЭВМ сопровождалось удвоением их быстродействия каждые 1.5-2 года. Это обеспечивалось и повышением тактовой частоты и совершенствованием архитектуры (параллельное и конвейерное выполнение команд). В течение нескольких десятилетий развитие ЭВМ сопровождалось удвоением их быстродействия каждые 1.5-2 года. Это обеспечивалось и повышением тактовой частоты и совершенствованием архитектуры (параллельное и конвейерное выполнение команд). Узким местом стала оперативная память. Знаменитый закон Мура, так хорошо работающий для процессоров, совершенно не применим для памяти, где скорости доступа удваиваются в лучшем случае каждые 6 лет. Совершенствовались системы кэш-памяти, увеличивался объем, усложнялись алгоритмы ее использования. Для процессора Intel Itanium: Latency to L1: 1-2 cycles Latency to L2: 5 - 7 cycles Latency to L3: 12 - 21 cycles Latency to memory: 180 – 225 cycles Важным параметром становится - GUPS (Giga Updates Per Second)

Время Время





 1,73 ГГц Intel Itanium 9350 (Tukwila) 1,73 ГГц 4 яд")
Intel Itanium 9350 (Tukwila) 1,73 ГГц Intel Itanium 9350 (Tukwila) 1,73 ГГц 4 ядeр 8 потоков с технологией Intel Hyper-Threading 24 МБ L3 кэш-памяти технология Intel QuickPath Interconnect технология Intel Turbo Boost

IBM Power7 IBM Power7 3,5 - 4,0 ГГц 8 ядер x 4 нити Simultaneuos MultiThreading L1 64КБ L2 256 КБ L3 32 МБ встроенный контроллер памяти


Автоматическое / автоматизированное распараллеливание Автоматическое / автоматизированное распараллеливание Библиотеки нитей Win32 API POSIX Библиотеки передачи сообщений MPI OpenMP


Polaris, CAPO, WPP, SUIF, VAST/Parallel, OSCAR, Intel/OpenMP, UTL Polaris, CAPO, WPP, SUIF, VAST/Parallel, OSCAR, Intel/OpenMP, UTL icc -parallel pi.c pi.c(8): (col. 5) remark: LOOP WAS AUTO-PARALLELIZED. pi.c(8): (col. 5) remark: LOOP WAS VECTORIZED. pi.c(8): (col. 5) remark: LOOP WAS VECTORIZED. В общем случае, автоматическое распараллеливание затруднено: косвенная индексация (A[B[i]]); указатели (ассоциация по памяти); сложный межпроцедурный анализ.
, CAPTools/ParaWise, BERT77, FORGE Magic/DM, ДВО")
Intel/GAP (Guided Auto-Parallel), CAPTools/ParaWise, BERT77, FORGE Magic/DM, ДВОР (Диалоговый Высокоуровневый Оптимизирующий Распараллеливатель), САПФОР (Система Автоматизации Параллелизации ФОРтран программ) Intel/GAP (Guided Auto-Parallel), CAPTools/ParaWise, BERT77, FORGE Magic/DM, ДВОР (Диалоговый Высокоуровневый Оптимизирующий Распараллеливатель), САПФОР (Система Автоматизации Параллелизации ФОРтран программ) for (i=0; i<n; i++) { if (A[i] > 0) {b=A[i]; A[i] = 1 / A[i]; } if (A[i] > 1) {A[i] += b;} } icc -guide -parallel test.cpp
: remark #30521: (PAR) Loop at line 49 cannot be parallelized due to")
test.cpp(49): remark #30521: (PAR) Loop at line 49 cannot be parallelized due to conditional assignment(s) into the following variable(s): b. This loop will be parallelized if the variable(s) become unconditionally initialized at the top of every iteration. [VERIFY] Make sure that the value(s) of the variable(s) read in any iteration of the loop must have been written earlier in the same iteration. test.cpp(49): remark #30521: (PAR) Loop at line 49 cannot be parallelized due to conditional assignment(s) into the following variable(s): b. This loop will be parallelized if the variable(s) become unconditionally initialized at the top of every iteration. [VERIFY] Make sure that the value(s) of the variable(s) read in any iteration of the loop must have been written earlier in the same iteration. test.cpp(49): remark #30525: (PAR) If the trip count of the loop at line 49 is greater than 188, then use "#pragma loop count min(188)" to parallelize this loop. [VERIFY] Make sure that the loop has a minimum of 188 iterations. #pragma loop count min (188) for (i=0; i<n; i++) { b = A[i]; if (A[i] > 0) {A[i] = 1 / A[i];} if (A[i] > 1) {A[i] += b;} }







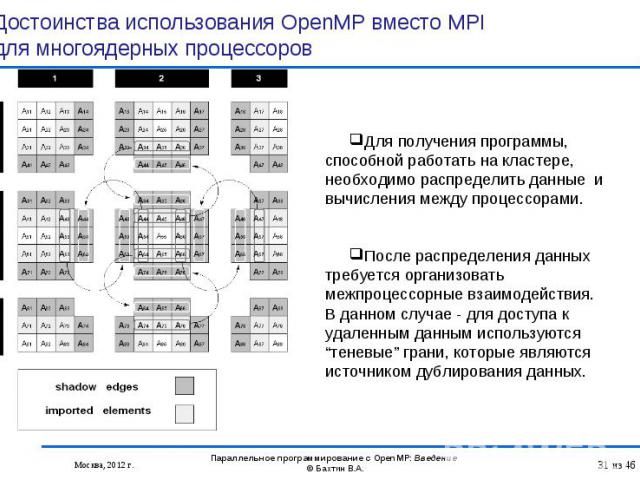
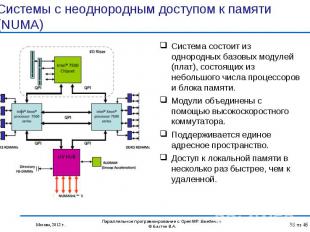
Возможность инкрементального распараллеливания Возможность инкрементального распараллеливания Упрощение программирования и эффективность на нерегулярных вычислениях, проводимых над общими данными Ликвидация дублирования данных в памяти, свойственного MPI-программам Объем памяти пропорционален быстродействию процессора. В последние годы увеличение производительности процессора достигается увеличением числа ядер, при этом частота каждого ядра не увеличивается. Наблюдается тенденция к сокращению объема оперативной памяти, приходящейся на одно ядро. Присущая OpenMP экономия памяти становится очень важна. Наличие локальных и/или разделяемых ядрами КЭШей будут учитываться при оптимизации OpenMP-программ компиляторами, что не могут делать компиляторы с последовательных языков для MPI-процессов.

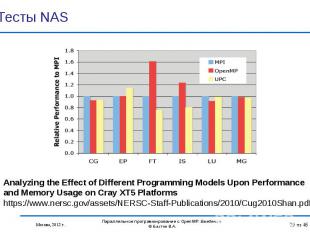


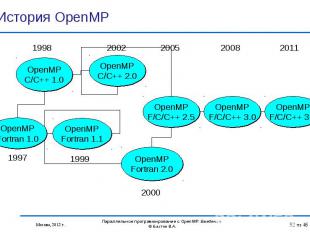

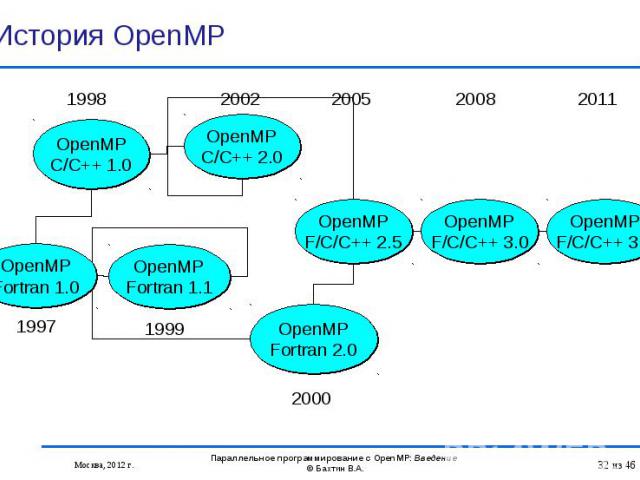
OpenMP 3.1: OpenMP 3.1: Intel 12.0: Linux, Windows and MacOS Oracle Solaris Studio12.3: Linux and Solaris GNU gcc (4.7.0) OpenMP 3.0: PGI 8.0: Linux and Windows IBM 10.1: Linux and AIX Cray: Cray XT series Linux environment Absoft Pro FortranMP: 11.1 NAG Fortran Complier 5.3 Предыдущие версии OpenMP: Lahey/Fujitsu Fortran 95 PathScale HP Microsoft Visual Studio 2008 C++

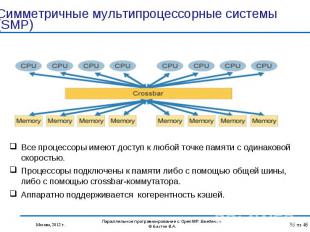













")






