

, авторских …")


 и графических файлов, включая задание контактных областей для гиперграфики. 2. Подготовка текста и графических иллюстраций с…")

. Представление и взаимодействие со справочником обеспечивает программа WINHELP.EXE, входящая в состав Windows. HLP-файл формируется на основе файлов с текстом в фор…")
. Для вызова справочника из приложения слу…")


. Предназначена для построения электронных гипертекстовых изданий большого объема. Разработана в МЭИ (ТУ). HyperRef поддерживает следующие типы ин…")

; пользовательская программа для работы с ГТ (исполнитель); набор утилит, позволяющих осуществлять поточный ввод информации, контролировать и восстанавливать целостность электронных гипертекстовых докуме…")

; поддержка ускоренного просмотра; формирование отчетов; поддержка формирования и корректировки тезауруса.")

 заголовков ИСС; алфавитная сортировка (лексико-графическое упорядочение) заголовков ИСС; контекстный поиск ИСС по заголовку; поддержка ускоренного просмотра словаря; печать информации из словаря.")

.")
. Признаки документа, отражающие его содержание в ИПС, называют поисковым образом, а признаки запро…")
. Процед…")

 и библиографическое описание документа (книги, события, предмета). Реферат (аннотация) выражается на ЕЯ и отражает основные характеристики документа, представляю…")






 об объектах ПрО. Подобные ИПС реализуются, в частности, на основе реляционных БД. С точки зрения обеспечения релевантности результатов поиска (выборки данных) запросу фактог…")




 0. При r=0 документы di и dj эквивалентны по смыслу. Для семантически несопоставимых документов не r определена. Зададим на D оценку смысловой близости пары документов r(di,dj) 0. При r…")
=0) ему точно соответствует документ dj. Поисковый запрос может рассматриваться как виртуальный документ z. В идеальном случае (r(z,dj)=0) ему точно соотве…")








Презентация на тему: Интеллектуальные информационные системы 2


Благодаря широкому использованию ГТ в ИС практически любой инструментарий разработки ИС включает функции для построения ГТ. В частности, данные функции реализуются в средствах разработки электронной документации (например, Adobe Acrobat), авторских системах, редакторах презентаций, издательских системах, редакторах web-страниц и др. Благодаря широкому использованию ГТ в ИС практически любой инструментарий разработки ИС включает функции для построения ГТ. В частности, данные функции реализуются в средствах разработки электронной документации (например, Adobe Acrobat), авторских системах, редакторах презентаций, издательских системах, редакторах web-страниц и др. Существует также специализированный инструментарий:

- стандартные технологии построения и работы с гипертекстовыми справочниками для платформы Windows. Они позволяют формировать самые разнообразные ГТ: - стандартные технологии построения и работы с гипертекстовыми справочниками для платформы Windows. Они позволяют формировать самые разнообразные ГТ: электронные руководства, справочники, энциклопедии, пособия и др. Однако главное назначение данных технологий — реализация контекстно-зависимых гипертекстовых справочников по программным продуктам. Такие справочники являются неотъемлемым компонентом прикладных программных систем. По умолчанию они вызываются клавишей F1 или через меню «Справка». Информация, отображаемая в окне справочника после его вызова, зависит от текущего режима работы приложения, с которым он связан. Поэтому подобные справочники называются контекстно-зависимыми

Определение структуры справочника и его разделов. Определение структуры справочника и его разделов. Этот этап является наиболее сложным и трудно формализуемым. В рамках него специфицируются: назначение продукта, для которого создается справочник; категории пользователей продукта; рыночный сектор, на который ориентирован продукт; функции и характеристики продукта, представляемые в справочнике; основные разделы справочника и их примерное содержание; соглашения, фиксирующие стиль, дизайн и оформление справочника.

2. Подготовка текста и графических иллюстраций справочника. Определение гипертекстовых ссылок. Формирование файлов тем (ИСС) и графических файлов, включая задание контактных областей для гиперграфики. 2. Подготовка текста и графических иллюстраций справочника. Определение гипертекстовых ссылок. Формирование файлов тем (ИСС) и графических файлов, включая задание контактных областей для гиперграфики. 3. Создание файла проекта справочника.

4. Компиляция исходных файлов тем, графических файлов и файла проекта с формированием файла справочника. 4. Компиляция исходных файлов тем, графических файлов и файла проекта с формированием файла справочника. 5. Программная реализация модуля приложения, обеспечивающего доступ к справочнику. 6. Тестирование и отладка справочника.

Гипертекст в формате WinHelp реализуется в виде файла с расширением HLP (help-файла). Представление и взаимодействие со справочником обеспечивает программа WINHELP.EXE, входящая в состав Windows. HLP-файл формируется на основе файлов с текстом в формате RTF с помощью специального компилятора. Для вызова справочника из приложения служит функция Windows API WinHelp(). Гипертекст в формате WinHelp реализуется в виде файла с расширением HLP (help-файла). Представление и взаимодействие со справочником обеспечивает программа WINHELP.EXE, входящая в состав Windows. HLP-файл формируется на основе файлов с текстом в формате RTF с помощью специального компилятора. Для вызова справочника из приложения служит функция Windows API WinHelp().

Гипертекст в формате HTML Help реализуется в виде файла с расширением СНМ. Представление и взаимодействие со справочником обеспечивают программные компоненты браузера Internet Explorer (начиная с версии 4.0). Для вызова справочника из приложения служит функция HTML Help API HtmlHelp(). Гипертекст в формате HTML Help реализуется в виде файла с расширением СНМ. Представление и взаимодействие со справочником обеспечивают программные компоненты браузера Internet Explorer (начиная с версии 4.0). Для вызова справочника из приложения служит функция HTML Help API HtmlHelp().

мощные средства языка HTML, включая каскадные таблицы стилей; мощные средства языка HTML, включая каскадные таблицы стилей; возможности использования компонентов ActiveX и скриптов; тесная интеграция с технологиями Internet; возможность создания составных гипертекстовых справочников, объединяемых во время выполнения. Информация в СНМ-файле хранится в сжатом виде. Степень компрессии составляет примерно 8:1.

Гипертекст в формате HTML Help может быть разработан с помощью различных инструментальных средств. Наиболее популярными из них являются HTML Help Workshop фирмы Microsoft и KeyTools фирмы KeyWorks Software. Система Anet Help Tool российской фирмы Anet Soft позволяет создавать ГТ в формате как HTML Help, так и WinHelp. Гипертекст в формате HTML Help может быть разработан с помощью различных инструментальных средств. Наиболее популярными из них являются HTML Help Workshop фирмы Microsoft и KeyTools фирмы KeyWorks Software. Система Anet Help Tool российской фирмы Anet Soft позволяет создавать ГТ в формате как HTML Help, так и WinHelp.

Предназначена для построения электронных гипертекстовых изданий большого объема. Разработана в МЭИ (ТУ). Предназначена для построения электронных гипертекстовых изданий большого объема. Разработана в МЭИ (ТУ). HyperRef поддерживает следующие типы информационных объектов: текстовые экранные страницы, графические изображения, исполняемые модули.

Объекты объединяются как в линейные последовательности, метафорой которых является глава или раздел книги, так и в гипертекстовую сеть. В визуальных объектах могут быть определены интерактивные элементы, используемые для организации гиперссылок. Объекты объединяются как в линейные последовательности, метафорой которых является глава или раздел книги, так и в гипертекстовую сеть. В визуальных объектах могут быть определены интерактивные элементы, используемые для организации гиперссылок. HyperRef поддерживает типизацию гиперссылок и содержит средства навигации по ГТ с учетом ограничений, обусловленных типами ссылок.
; пользовательская программа для р")
диалоговый инструментарий автора (конструктор); пользовательская программа для работы с ГТ (исполнитель); набор утилит, позволяющих осуществлять поточный ввод информации, контролировать и восстанавливать целостность электронных гипертекстовых документов и т. д. В HyperRef предусмотрены средства, присущие фактографическим и полнотекстовым БД: словари ключевых слов, оглавления, средства выполнения сложных запросов и автоматической индексации текстов.

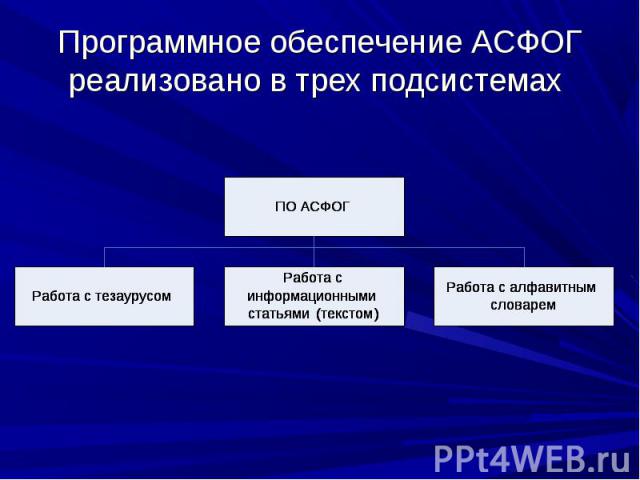
создана в МЭСИ, предназначена для моделирования экономических объектов и процессов на основе представления информационного фонда ПрО в виде ГТ. создана в МЭСИ, предназначена для моделирования экономических объектов и процессов на основе представления информационного фонда ПрО в виде ГТ. АСФОГ целесообразно использовать для моделирования слабоструктурированных ПрО, когда поиск текстовой информации в традиционных линейных и иерархических структурах неэффективен из-за их неадекватности реальной сетевой структуре информационных объектов, представляющих эти ПрО.
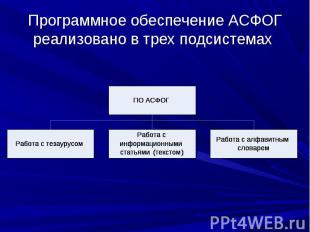

выполняет следующие функции: выполняет следующие функции: поиск в тезаурусе (поиск по связям с учетом их типов, контекстный поиск по связям); поддержка ускоренного просмотра; формирование отчетов; поддержка формирования и корректировки тезауруса.

создание ИСС с помощью текстового редактора типа Word; создание ИСС с помощью текстового редактора типа Word; коррекция ИСС; доступ к ИСС; формирование и печать отчетов по ИСС; импорт и экспорт файлов, содержащих ИСС.
 заголовков ИСС; алфавит")
алфавитная сортировка (лексико-графическое упорядочение) заголовков ИСС; алфавитная сортировка (лексико-графическое упорядочение) заголовков ИСС; контекстный поиск ИСС по заголовку; поддержка ускоренного просмотра словаря; печать информации из словаря.

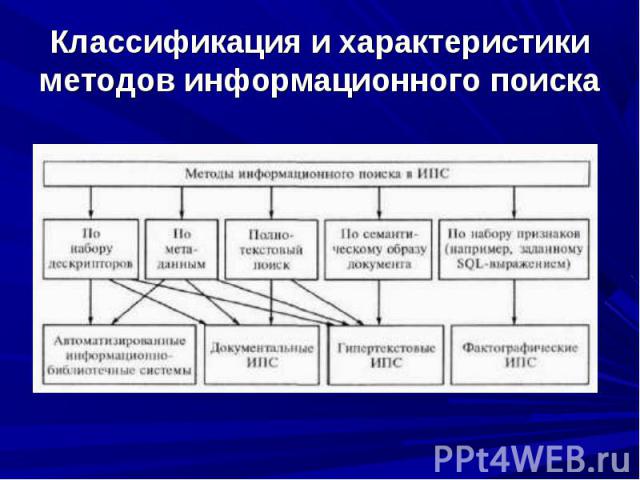
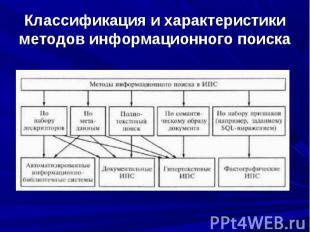
Гипертекстовая информационная технология используется при организации больших массивов текстовых документов и реализации методов поиска информации в них. Гипертекстовая информационная технология используется при организации больших массивов текстовых документов и реализации методов поиска информации в них. Информационный поиск — совокупность операций, методов и процедур, направленных на отбор данных, хранящихся в ИС и соответствующих заданным условиям.
.")
документальные; фактографические; гипертекстовые (ГИПС).

Документальные ИПС хранят и выдают сведения о документах, основное содержимое которых представлено в виде связанного текста на естественном языке (ЕЯ). Признаки документа, отражающие его содержание в ИПС, называют поисковым образом, а признаки запроса к ИПС — поисковым предписанием. Документальные ИПС хранят и выдают сведения о документах, основное содержимое которых представлено в виде связанного текста на естественном языке (ЕЯ). Признаки документа, отражающие его содержание в ИПС, называют поисковым образом, а признаки запроса к ИПС — поисковым предписанием.

Процедура перевода документа и запроса в форму представления, принятую в ИПС, называется индексированием. При сопоставлении поискового образа и поискового предписания используется тот или иной критерий смыслового соответствия (релевантности). Процедура перевода документа и запроса в форму представления, принятую в ИПС, называется индексированием. При сопоставлении поискового образа и поискового предписания используется тот или иной критерий смыслового соответствия (релевантности).

Первые ИПС были предназначены для поиска книг в библиотеках и получили название библиографических. Позже их стали применять и для поиска документов в больших хранилищах и стали называть документальными Первые ИПС были предназначены для поиска книг в библиотеках и получили название библиографических. Позже их стали применять и для поиска документов в больших хранилищах и стали называть документальными

Основным объектом информационного фонда документальной ИПС является аннотация (реферат) и библиографическое описание документа (книги, события, предмета). Реферат (аннотация) выражается на ЕЯ и отражает основные характеристики документа, представляющие интерес для пользователей. Предполагается, что в подобном описании можно выделить ряд слов и словосочетаний, число которых значительно меньше общего числа слов в описании. В то же время выделенная информация достаточно точно характеризует описание. Такие слова и словосочетания называются ключевыми словами или дескрипторами. Основным объектом информационного фонда документальной ИПС является аннотация (реферат) и библиографическое описание документа (книги, события, предмета). Реферат (аннотация) выражается на ЕЯ и отражает основные характеристики документа, представляющие интерес для пользователей. Предполагается, что в подобном описании можно выделить ряд слов и словосочетаний, число которых значительно меньше общего числа слов в описании. В то же время выделенная информация достаточно точно характеризует описание. Такие слова и словосочетания называются ключевыми словами или дескрипторами.

Запрос к документальной ИПС формулируется в виде перечня дескрипторов, которые по мнению пользователя характеризуют искомый документ. Запрос к документальной ИПС формулируется в виде перечня дескрипторов, которые по мнению пользователя характеризуют искомый документ. При вводе в ИПС нового объекта (реферата) его дескрипторы автоматически включаются в словарь дескрипторов. Каждому дескриптору присваивается номер, называемый индексом дескриптора. Совокупность индексов, соответствующих полному набору дескрипторов реферата, составляет его поисковый образ. Новый поисковый образ снабжается уникальным идентификатором (регистрируется) и включается в массив поисковых образов. Тем же идентификатором помечается новый реферат, заносимый в массив рефератов.

Запрос, сформулированный на ЕЯ, подвергается анализу, в рамках которого в нем выделяются дескрипторы, входящие в словарь дескрипторов. Их совокупность образует поисковое предписание, соответствующее запросу. Оно сопоставляется с поисковыми образами, в результате чего определяется их релевантность. Если поисковый образ и предписание релевантны, то из поискового образа извлекается идентификатор реферата, выдаваемого пользователю. Ответом на запрос является множество рефератов, соответствующих отобранным в процессе поиска идентификаторам. Запрос, сформулированный на ЕЯ, подвергается анализу, в рамках которого в нем выделяются дескрипторы, входящие в словарь дескрипторов. Их совокупность образует поисковое предписание, соответствующее запросу. Оно сопоставляется с поисковыми образами, в результате чего определяется их релевантность. Если поисковый образ и предписание релевантны, то из поискового образа извлекается идентификатор реферата, выдаваемого пользователю. Ответом на запрос является множество рефератов, соответствующих отобранным в процессе поиска идентификаторам.

В целях ускорения поиска для каждого дескриптора в словаре дескрипторов указывается список идентификаторов рефератов, в которых он встречается. Такая информационная структура ИПС называется индексом. В целях ускорения поиска для каждого дескриптора в словаре дескрипторов указывается список идентификаторов рефератов, в которых он встречается. Такая информационная структура ИПС называется индексом.

С помощью дескрипторов можно лишь приблизительно отразить смысл документов. Это же относится к переводу запросов в поисковые предписания. Документальная ИПС может выдать рефераты, не относящиеся к поисковому запросу, или не найти рефераты, которые соответствуют ему. С помощью дескрипторов можно лишь приблизительно отразить смысл документов. Это же относится к переводу запросов в поисковые предписания. Документальная ИПС может выдать рефераты, не относящиеся к поисковому запросу, или не найти рефераты, которые соответствуют ему.

Документальный поиск относится к числу сложных информационных процессов, поскольку он связан с проблемой оценивания смыслового соответствия документа и запроса. Из-за субъективности и неоднозначности подобного оценивания этот вид поиска в принципе не может быть исчерпывающе точным и полным, в нем всегда будет присутствовать элемент нечеткости. Документальный поиск относится к числу сложных информационных процессов, поскольку он связан с проблемой оценивания смыслового соответствия документа и запроса. Из-за субъективности и неоднозначности подобного оценивания этот вид поиска в принципе не может быть исчерпывающе точным и полным, в нем всегда будет присутствовать элемент нечеткости.

Развитием поиска по дескрипторам является полнотекстовый поиск, реализуемый, например, в поисковых машинах Internet. В системах, использующих данный вид поиска, индекс формируется на основе всех слов и словосочетаний, содержащихся в документах, за исключением служебных неинформативных слов (союзов, предлогов, местоимений и т. п.). При индексировании с помощью словарей и средств морфологического анализа слова приводятся к базовой грамматической форме (именительный падеж, единственное число и т. д.). Развитием поиска по дескрипторам является полнотекстовый поиск, реализуемый, например, в поисковых машинах Internet. В системах, использующих данный вид поиска, индекс формируется на основе всех слов и словосочетаний, содержащихся в документах, за исключением служебных неинформативных слов (союзов, предлогов, местоимений и т. п.). При индексировании с помощью словарей и средств морфологического анализа слова приводятся к базовой грамматической форме (именительный падеж, единственное число и т. д.).
 об о")
В фактографических ИПС хранятся не документы, а собственно сведения (факты) об объектах ПрО. Подобные ИПС реализуются, в частности, на основе реляционных БД. С точки зрения обеспечения релевантности результатов поиска (выборки данных) запросу фактографический поиск в отличие от документального является точным и полным. В фактографических ИПС хранятся не документы, а собственно сведения (факты) об объектах ПрО. Подобные ИПС реализуются, в частности, на основе реляционных БД. С точки зрения обеспечения релевантности результатов поиска (выборки данных) запросу фактографический поиск в отличие от документального является точным и полным.

В гипертекстовых ИПС кроме содержимого документов отражается их семантическая структура. Поэтому по глубине формализации ГИПС занимают промежуточное положение между документальными и фактографическими ИПС. В гипертекстовых ИПС кроме содержимого документов отражается их семантическая структура. Поэтому по глубине формализации ГИПС занимают промежуточное положение между документальными и фактографическими ИПС.

Одно из направлений развития технологии документальных ИПС связано со структуризацией и унификацией сведений о документах. Такие сведения по отношению к исходным документам играют роль метаданных. Примером метаданных служит библиографическое описание, содержащее информацию об авторах документа, дате его создания, объеме, форме представления и т. д. Ключевые слова также относят к метаданным. Одно из направлений развития технологии документальных ИПС связано со структуризацией и унификацией сведений о документах. Такие сведения по отношению к исходным документам играют роль метаданных. Примером метаданных служит библиографическое описание, содержащее информацию об авторах документа, дате его создания, объеме, форме представления и т. д. Ключевые слова также относят к метаданным.

Поиск по метаданным сближает технологии документальных и фактографических ИПС. С одной стороны, метаданные представляют документы. С другой стороны, некоторые элементы метаданных допускают четкое определение релевантности запроса и записи в БД (экземпляра метаданных, ассоциируемых с конкретным документом), что характерно для фактографических ИПС. Поиск по метаданным сближает технологии документальных и фактографических ИПС. С одной стороны, метаданные представляют документы. С другой стороны, некоторые элементы метаданных допускают четкое определение релевантности запроса и записи в БД (экземпляра метаданных, ассоциируемых с конкретным документом), что характерно для фактографических ИПС. В настоящее время хранилища метаданных обычно реализуются на основе реляционных и XML-ориентированных БД и используют механизмы поиска, воплощаемые в соответствующих СУБД.

Введем следующие обозначения: Введем следующие обозначения: В данном контексте под документом будем понимать как собственно текстовый или гипертекстовый документ, так и отдельную запись в БД.
 0. При r=0 докум")
Зададим на D оценку смысловой близости пары документов r(di,dj) 0. При r=0 документы di и dj эквивалентны по смыслу. Для семантически несопоставимых документов не r определена. Зададим на D оценку смысловой близости пары документов r(di,dj) 0. При r=0 документы di и dj эквивалентны по смыслу. Для семантически несопоставимых документов не r определена. Введем оценки ряда важных свойств документов: S=(S1,S2,…,Sk), k>0. Пусть оценка каждого свойства Sj выражается действительным числом, принадлежащим некоторому интервалу. Для определенности примем, что чем больше значение S, тем важнее для пользователя документ.

Поисковый запрос может рассматриваться как виртуальный документ z. В идеальном случае (r(z,dj)=0) ему точно соответствует документ dj. Поисковый запрос может рассматриваться как виртуальный документ z. В идеальном случае (r(z,dj)=0) ему точно соответствует документ dj.

1. Найти 1. Найти Если , то в D нет докуметов, релевантных запросу. При |Dj|=1 есть единственный подходящий документ. Если |Dj|>1, то таких документов несколько 2. Найти , где Δ - оценка наибольшего допустимого расхождения смыслов запроса и искомых документов.

3. Найти . Результатом поиска служит подмножество документов, которым приписана наибольшая оценка важности j-го свойства. Обобщением этого варианта является векторный поиск, учитывающий оценки нескольких свойств. 3. Найти . Результатом поиска служит подмножество документов, которым приписана наибольшая оценка важности j-го свойства. Обобщением этого варианта является векторный поиск, учитывающий оценки нескольких свойств. 4. Комбинированный поиск: найти Интеллектуальные возможности ИПС в части функций информационного поиска обусловлены способами задания и вычисления r и S.

Эффективность информационного поиска документов, обеспечиваемая ИПС, оценивается по информационной полноте и информационному шуму. Названные показатели выражаются коэффициентами полноты и шума соответственно. Коэффициенты и принимают значения в интервале от 0 до 1. В некоторых источниках эти коэффициенты выражают в процентах. Эффективность информационного поиска документов, обеспечиваемая ИПС, оценивается по информационной полноте и информационному шуму. Названные показатели выражаются коэффициентами полноты и шума соответственно. Коэффициенты и принимают значения в интервале от 0 до 1. В некоторых источниках эти коэффициенты выражают в процентах.



Успешность поиска формально определяется степенью совпадения множеств Di и Di0. Успешность поиска формально определяется степенью совпадения множеств Di и Di0.
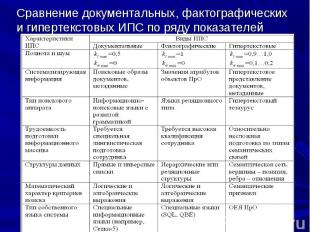

Системы контекстной помощи можно рассматривать как частный случай интеллектуальных гипертекстовых и естественно-языковых систем. В отличие от обычных систем помощи, навязывающих пользователю схему поиска требуемой информации, в системах контекстной помощи пользователь описывает проблему (ситуацию), а система с помощью дополнительного диалога ее конкретизирует и сама выполняет поиск относящихся к ситуации рекомендаций. Такие системы относятся к классу систем распространения знаний (Knowledge Publishing) и создаются как приложение к системам документации (например, технической документации по эксплуатации товаров). Системы контекстной помощи можно рассматривать как частный случай интеллектуальных гипертекстовых и естественно-языковых систем. В отличие от обычных систем помощи, навязывающих пользователю схему поиска требуемой информации, в системах контекстной помощи пользователь описывает проблему (ситуацию), а система с помощью дополнительного диалога ее конкретизирует и сама выполняет поиск относящихся к ситуации рекомендаций. Такие системы относятся к классу систем распространения знаний (Knowledge Publishing) и создаются как приложение к системам документации (например, технической документации по эксплуатации товаров).











