
 Харламов А.А. (NVidia)")

 Самая быстрая – shared (on-chip) Самая медленная – глобальная (DRAM) Для ряда случаев можно использовать кэшируемую константную и текстурную память Доступ к памяти в CUDA идет отдельно для каждой половины warp’а (hal…")





![Обращения идут через 32/64/128-битовые слова Обращения идут через 32/64/128-битовые слова При обращении к t[i] sizeof( t [0] ) равен 4/8/16 байтам t [i] выровнен по sizeof ( t [0] ) Вся выделяемая память всегда выровнена по 256 байт](https://fs1.ppt4web.ru/images/95232/150472/640/img8.jpg "Обращения идут через 32/64/128-битовые слова Обращения идут через 32/64/128-битовые слова При обращении к t[i] sizeof( t [0] ) равен 4/8/16 байтам t [i] выровнен по sizeof ( t [0] ) Вся выделяемая память всегда выровнена по 256 байт")








 и для каждого блока проводится отдельная транзакция Для 1.2/1.3 порядок в котором нити обращаются …")








Презентация на тему: Иерархия памяти CUDA
 Харламов А.А. (NVidia)")
Лекторы: Лекторы: Боресков А.В. (ВМиК МГУ) Харламов А.А. (NVidia)

 Самая быстрая – shared (on-chip) Самая медленна")
Самая быстрая – shared (on-chip) Самая быстрая – shared (on-chip) Самая медленная – глобальная (DRAM) Для ряда случаев можно использовать кэшируемую константную и текстурную память Доступ к памяти в CUDA идет отдельно для каждой половины warp’а (half-warp)

Основа оптимизации – оптимизация работы с памятью Основа оптимизации – оптимизация работы с памятью Максимальное использование shared-памяти Использование специальных паттернов доступа к памяти, гарантирующих эффективный доступ Паттерны работают независимо в пределах каждого half-warp’а

Произведение двух квадратных матриц A и B размера N*N, N кратно 16 Произведение двух квадратных матриц A и B размера N*N, N кратно 16 Матрицы расположены в глобальной памяти По одной нити на каждый элемент произведения 2D блок – 16*16 2D grid




Обращения идут через 32/64/128-битовые слова Обращения идут через 32/64/128-битовые слова При обращении к t[i] sizeof( t [0] ) равен 4/8/16 байтам t [i] выровнен по sizeof ( t [0] ) Вся выделяемая память всегда выровнена по 256 байт

struct vec3 struct vec3 { float x, y, z; };

Compute Caps. – доступная версия CUDA Compute Caps. – доступная версия CUDA Разные возможности HW Пример: В 1.1 добавлены атомарные операции в global memory В 1.2 добавлены атомарные операции в shared memory В 1.3 добавлены вычисления в double Узнать доступный Compute Caps. можно через cudaGetDeviceProperties() См. CUDAHelloWorld Сегодня Compute Caps: Влияет на правила работы с глобальной памятью

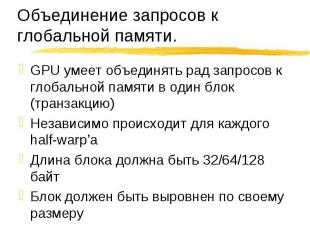

Нити обращаются к Нити обращаются к 32-битовым словам, давая 64-байтовый блок 64-битовым словам, давая 128-байтовый блок Все 16 слов лежат в пределах блока k-ая нить half-warp’а обращается к k-му слову блока
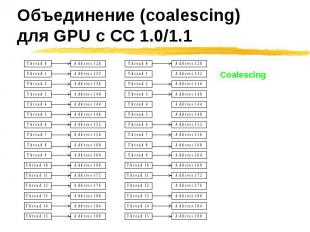
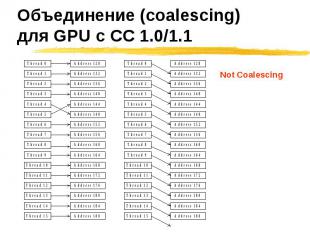

Нити обращаются к Нити обращаются к 8-битовым словам, дающим один 32-байтовы сегмент 16-битовым словам, дающим один 64-байтовый сегмент 32-битовым словам, дающим один 128-байтовый сегмент Получающийся сегмент выровнен по своему размеру

Если хотя бы одно условие не выполнено Если хотя бы одно условие не выполнено 1.0/1.1 – 16 отдельных транзаций 1.2/1.3 – объединяет их в блоки (2,3,…) и для каждого блока проводится отдельная транзакция Для 1.2/1.3 порядок в котором нити обращаются к словам внутри блока не имеет значения (в отличии от 1.0/1.1)

Можно добиться заметного увеличения скорости работы с памятью Можно добиться заметного увеличения скорости работы с памятью Лучше использовать не массив структур, а набор массивов отдельных компонент – это позволяет использовать coalescing


Традиционные методы ориентированы на последовательное вычисление элементов и нам не подходят Традиционные методы ориентированы на последовательное вычисление элементов и нам не подходят Есть еще итеративные методы




CUDA.CS.MSU.SU CUDA.CS.MSU.SU Место для вопросов и дискуссий Место для материалов нашего курса Место для ваших статей! Если вы нашли какой-то интересный подход! Или исследовали производительность разных подходов и знаете, какой из них самый быстрый! Или знаете способы сделать работу с CUDA проще! www.steps3d.narod.ru www.nvidia.ru




")







