

. В коммуникационных операциях типа точка-точка всегда участвуют 2 процесса: передающий и принимающий. В MPI имеется множество функций, реализующ…")








 объект \"запрос обмена\" (request) для связи между функциями обмена и функциями опроса их завершения. Неблокирующие операции используют специальный скрытый (opaque) объект \"…")








Презентация на тему: Коммуникационные операции «точка-точка


К операциям этого типа относятся две представленные выше коммуникационные процедуры (MPI_Send, MPI_Recv). В коммуникационных операциях типа точка-точка всегда участвуют 2 процесса: передающий и принимающий. В MPI имеется множество функций, реализующих такой тип обмена. Многообразие объясняется возможностью организации таких обменов множеством способов. Описанные в предыдущем разделе функции реализуют стандартный режим с блокировкой. К операциям этого типа относятся две представленные выше коммуникационные процедуры (MPI_Send, MPI_Recv). В коммуникационных операциях типа точка-точка всегда участвуют 2 процесса: передающий и принимающий. В MPI имеется множество функций, реализующих такой тип обмена. Многообразие объясняется возможностью организации таких обменов множеством способов. Описанные в предыдущем разделе функции реализуют стандартный режим с блокировкой.

Блокирующие функции подразумевают полное окончание операции после выхода из процедуры, т.е. вызывающий процесс блокируется, пока операция не будет завершена. Блокирующие функции подразумевают полное окончание операции после выхода из процедуры, т.е. вызывающий процесс блокируется, пока операция не будет завершена.

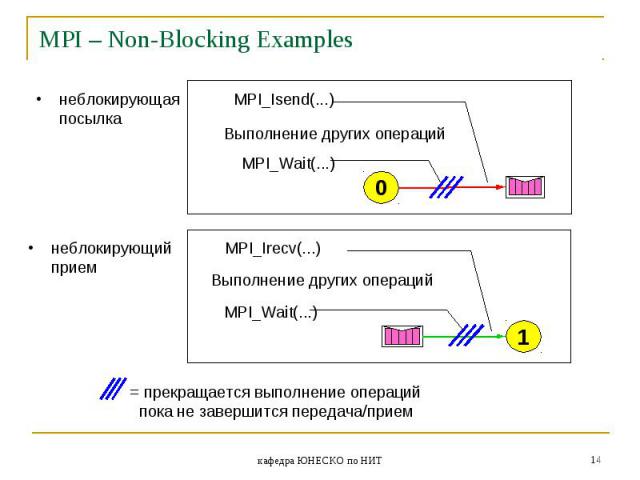
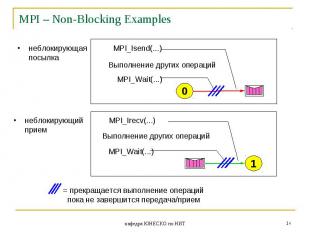
Неблокирующие функции подразумевают совмещение операций обмена с другими операциями, поэтому неблокирующие функции передачи и приема по сути дела являются функциями инициализации соответствующих операций. Для опроса завершенности операции (и принудительного завершения) вводятся дополнительные функции. Неблокирующие функции подразумевают совмещение операций обмена с другими операциями, поэтому неблокирующие функции передачи и приема по сути дела являются функциями инициализации соответствующих операций. Для опроса завершенности операции (и принудительного завершения) вводятся дополнительные функции.

Из таблицы хорошо виден принцип формирования имен функций. К именам базовых функций Send/Recv добавляются различные префиксы. Из таблицы хорошо виден принцип формирования имен функций. К именам базовых функций Send/Recv добавляются различные префиксы.


Процессор-отправитель ожидает информацию о том, когда получатель примет сообщение. Процессор-отправитель ожидает информацию о том, когда получатель примет сообщение. Пример, факс получатель присылает тег завершения приема.

Процессор-отправитель знает только когда сообщение ушло. Процессор-отправитель знает только когда сообщение ушло.

Неблокирующие операции немедленно возвращают управление программе. Программа выполняет следующие действия. Неблокирующие операции немедленно возвращают управление программе. Программа выполняет следующие действия. Для того, что бы спустя некоторое время убедиться, что неблокирующая функция передачи данных выполнена полностью, нужно вызвать функцию MPI_Test или MPI_Wait.

Использование неблокирующих коммуникационных операций более безопасно с точки зрения возникновения тупиковых ситуаций, а также может увеличить скорость работы программы за счет совмещения выполнения вычислительных и коммуникационных операций. Эти задачи решаются разделением коммуникационных операций на две стадии: инициирование операции и проверку завершения операции. Использование неблокирующих коммуникационных операций более безопасно с точки зрения возникновения тупиковых ситуаций, а также может увеличить скорость работы программы за счет совмещения выполнения вычислительных и коммуникационных операций. Эти задачи решаются разделением коммуникационных операций на две стадии: инициирование операции и проверку завершения операции.
 объект "запр")
Неблокирующие операции используют специальный скрытый (opaque) объект "запрос обмена" (request) для связи между функциями обмена и функциями опроса их завершения. Неблокирующие операции используют специальный скрытый (opaque) объект "запрос обмена" (request) для связи между функциями обмена и функциями опроса их завершения. Для прикладных программ доступ к этому объекту возможен только через вызовы MPI-функций. Если операция обмена завершена, подпрограмма проверки снимает "запрос обмена", устанавливая его в значение MPI_REQUEST_NULL. Снять "запрос обмена" без ожидания завершения операции можно подпрограммой MPI_Request_free.

Входные параметры: Входные параметры:

Входные параметры: Входные параметры:

Входные параметры: Входные параметры:

Входные параметры: Входные параметры:


Нулевой процесс выполняет продолжительный цикл и после его выполнения посылает первому процессору значение вычислений цикла при помощи коммуникационной функции MPI_Send; Нулевой процесс выполняет продолжительный цикл и после его выполнения посылает первому процессору значение вычислений цикла при помощи коммуникационной функции MPI_Send; A) Первый процесс засекает время t1, выполняет блокирующую функцию MPI_Recv, засекает время t2, выводит присланное значение и затраченное время на ожидание и прием посылки. B) Первый процесс засекает время t1, выполняет неблокирующую функцию MPI_Irecv, засекает время t2, выводит полученное значение и затраченное время на выполнение неблокирующей операции приема. C) Первый процессор засекает время t1, выполняет неблокирующую функцию MPI_Irecv, засекает время t2, выполняет операцию MPI_Wait, засекает время t3, выводит полученное значение и затраченное время на выполнение неблокирующей операции приема и ожидание получения посылки.

Каждый процессор помещает свой ранг в целочисленную переменную buf. Каждый процессор помещает свой ранг в целочисленную переменную buf. Каждый процессор пересылает переменную buf соседу справа. Каждый процессор суммирует принимаемое значение в переменную s, а затем передаёт принятое значение соседу справа. Пересылки по кольцу прекращаются, когда каждый процессор получит то значение, с которого начал пересылки: т.е. каждый процессор просуммирует ранги всех процессоров. С целью исключения взаимоблокировки используются неблокирующие пересылки MPI_Isend.

Замените в предыдущей задаче схему «Isend-Recv-Wait» на Sendrecv. Замените в предыдущей задаче схему «Isend-Recv-Wait» на Sendrecv.











