

 задач одновременно, а максимально возможная загрузка процессорных ресурсов. Процессоры, выполненные по технологии Hyper-Threading, одновременно обра…")



. Performance = …")
 Intel Smart Memory Access (Оптимизация доступа к памяти, в т.ч. Memory Disambiguation) Intel Advanced Smart Cache (Общий КЭШ 2го уровня…")

. 6 портов запуска (1 – Load, 2 – Store и 3 универ-сальных). Усовершенствованный бло…")

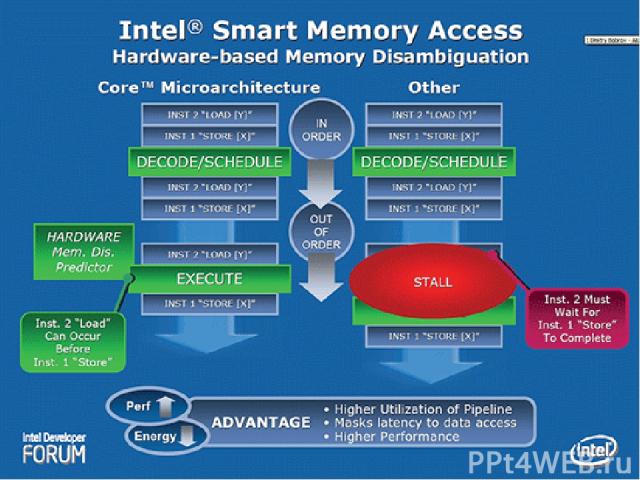
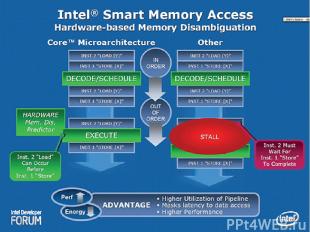
. Memory Disambiguation технология направлена на повышение эффективности работы алгоритмов внеочередного исполнения инструкций, осуществляющих чтение и …")


. Этот факт заставил инженеров Intel задуматься об ускор…")
 4 FP (FADD + FMUL + FLOAD + FSTORE) 3 SSE (128 bit)")

")






 КЭШ 1го уровня: 32+32 Кбайт 2го уровня: 512 Кбайт")

 256 GFLOPS с плавающей запятой 256 GOPS целочисленная арифметика 25 GFLOPS с плавающей запятой двойной точности")
Презентация на тему: Процессор

Современные микропроцессоры 900igr.net

Технология Hyper-Threading Главная цель применения Hyper-Threading — не выполнение двух (нескольких) задач одновременно, а максимально возможная загрузка процессорных ресурсов. Процессоры, выполненные по технологии Hyper-Threading, одновременно обраба-тывают две (несколько) нитей процессов, состоящие из потоков данных и команд двух (нескольких) разных приложений или различных частей одного.

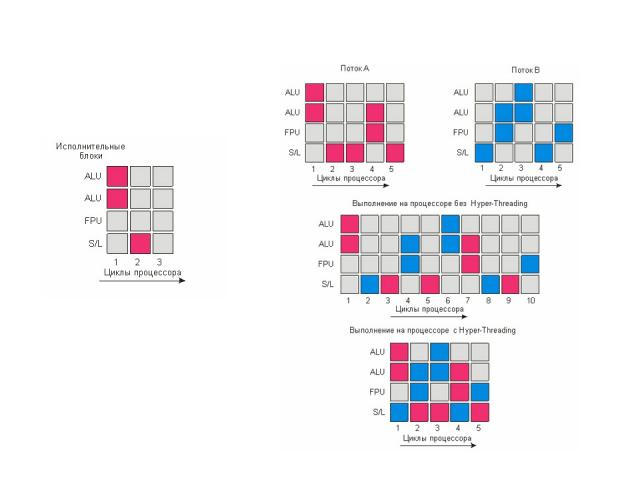
Система с двумя IA-32 процессорами и ЦП, построенный по технологии Hyper-Threading

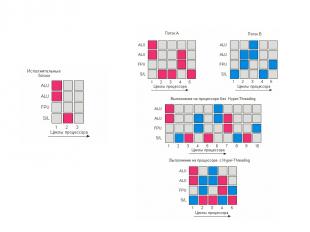
Загрузка процессоров Оранжевые и зеленые блоки работают, серые простаивают. 1 — выполнение 1 нити на обычном процессоре; 2 — выполнение 2 нитей на 2 разных процессорах стандартной 2-процессорной системой; 3 — одновременное выполне-ние 2 нитей на 1 процессоре с технологией Hyper-Threading; 4 — выполнение 4 нитей на 2 процессорах 2-процессор-ной системы с технологией Hyper-Threading.

Многоядерность

Многоядерность Пути увеличения быстродействия: наращивание тактовых частот, увеличение числа инструкций, исполня-емых за один такт, уменьшение числа операций, необходи-мых для обработки одних и тех же объёмов данных (SIMD инструкции). Performance = Frequency * IPC Power =

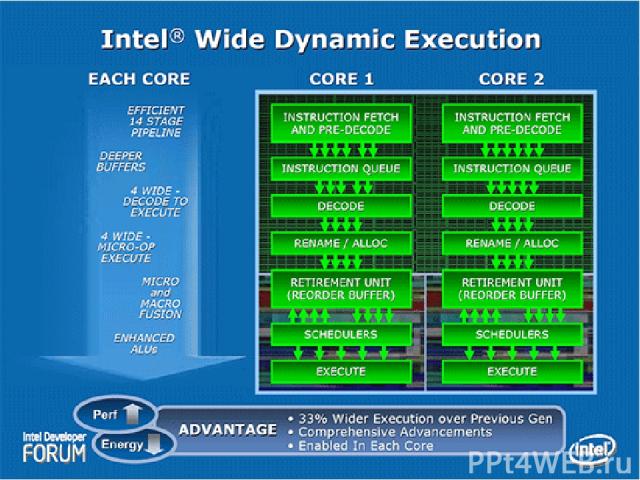
Особенности Core 2 Duo Intel Wide Dynamic Execution (14 стадий конвейера, до 4х инструкций за такт в каждом ядре) Intel Smart Memory Access (Оптимизация доступа к памяти, в т.ч. Memory Disambiguation) Intel Advanced Smart Cache (Общий КЭШ 2го уровня, динамически распределяемый между ядрами) Intel Advanced Digital Media Boost (128-битный SSE, расширенный набор команд) Intel Intelligent Power Capability Micro-ops fusion и macrofusion

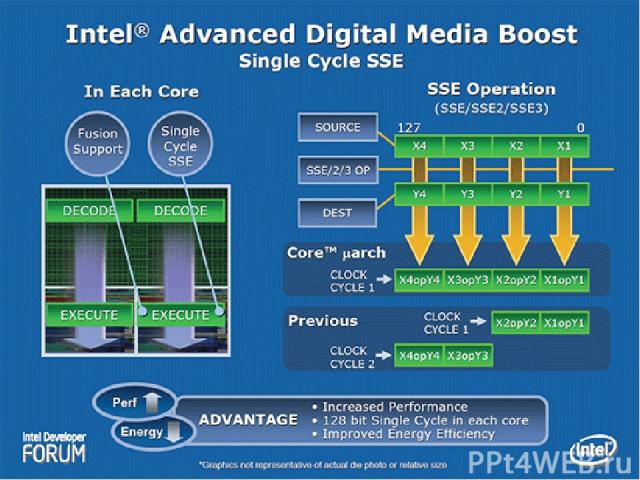
Особенности Core 2 Duo Intel Wide Dynamic Execution — технология выполнения большего количества команд за каждый такт, повышающая эффективность выполнения приложений и сокращающая энергопотребление. Каждое ядро может выполнять до 4-х инструкций одновременно с помощью 14-стадийного конвейера. Intel Intelligent Power Capability — технология, с помощью которой для исполнения задач активируется работа отдельных узлов чипа по мере необходимости, что значительно снижает энергопотребление системы в целом. Intel Advanced Smart Cache — технология использования общей для всех ядер кэш-памяти 2-го уровня, что снижает энергопотребление и повышает производительность, при этом, по мере необходимости, одно из ядер может использовать весь объём кэш-памяти при динамическом отключении другого ядра. Intel Smart Memory Access — технология оптимизации работы подсистемы памяти, сокращающая время отклика и повышающая пропускную способность подсистемы памяти. Intel Advanced Digital Media Boost — технология обработки 128-разрядных команд SSE, SSE2 и SSE3, широко используемых в мультимедийных и графических приложениях, за один такт.
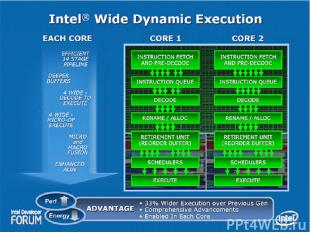

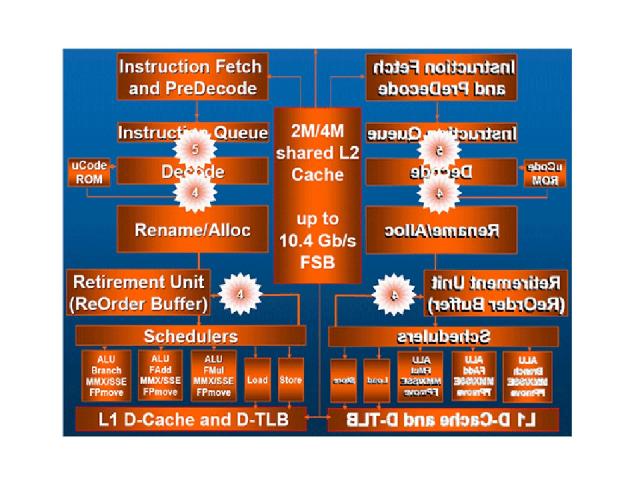
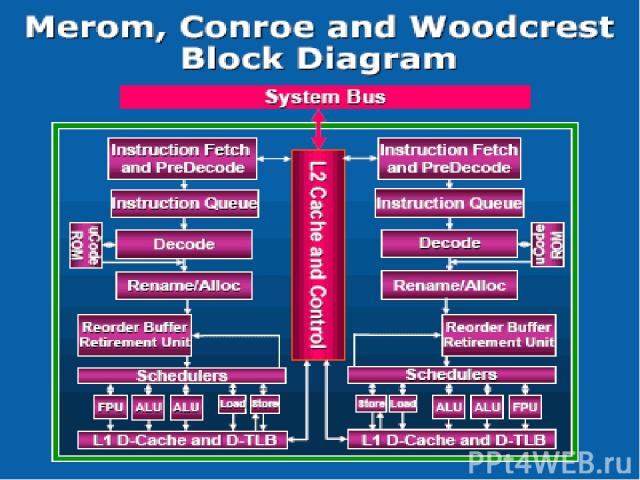
Intel Wide Dynamic Execution Каждое ядро выбирает из кода и исполняет до 4 x86 инструкций одновременно. Имеет 4 декодера (1 для сложных инструкций и 3 – для простых). 6 портов запуска (1 – Load, 2 – Store и 3 универ-сальных). Усовершенствованный блок предсказания переходов. Увеличены буферы команд, используемые на различных этапах анализа кода для оптимизации скорости исполнения, Длина конвейера составляет 14 стадий. Процессоры с микроархитектурой Core обладают поддержкой 64-битных расширений Enhanced Memory 64 Technology (EM64T).

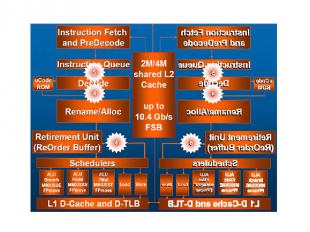
Intel Advanced Smart Cache Нет необходимости поддерживать когерентность. Динамически распределяется между ядрами.

Intel Smart Memory Access 6 Блоков предвыборки (2 для КЭШа 2го уровня, по 2 для КЭШей 1го уровня). Memory Disambiguation технология направлена на повышение эффективности работы алгоритмов внеочередного исполнения инструкций, осуществляющих чтение и запись данных в памяти. Она использует алгоритмы, позволяющие с высокой вероятностью устанавливать зависимость последовательных команд сохранения и загрузки данных, и даёт возможность, таким образом, применять внеочередное выполнение инструкций к этим командам.

Micro-ops fusion и macrofusion технологии Обе технологии увеличивают числа исполняемых команд за такт. 1. Команда – это «связанные» декодером зависимые микро-инструкции, на которые распа-дается x86-команда. Это позволяет избежать ненужных простоев процессора, если связанные микроинструкции оказываются оторванными друг от друга в результате работы алгоритмов внеоче-редного выполнения. 2. Команда -- связанные между собой после-довательных x86-команд, например, сравнение со следующим за ним условным переходом, пред-ставляются внутри процессора одной микроинст-рукцией. Таким путём достигается как увеличение темпа исполнения кода, так и некоторая экономия энергии.

Macro-fusion технологии

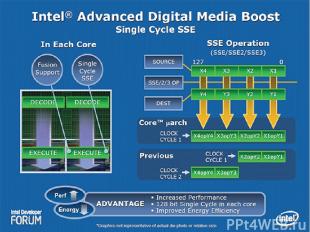
Intel Advanced Digital Media Boost Современное ПО позволяет работать со 128-битовыми операндами различного характера (векто-рами и целочисленными либо вещественными данными повышенной точности). Этот факт заставил инженеров Intel задуматься об ускорении работы SSE блоков процессора, тем более что до настоящего времени процессоры Intel испол-няли одну SSE-инструкцию, работающую с 128-битными операндами, лишь за два такта. Один такт тратился на обработку старших 64 бит. Второй такт – на обработку младших 64 бит. Микроархитектура Core позволяет ускорить работу с SSE инструкциями в два раза.

Технические характеристики Core 2 Duo L1 DCache 32K 8-way L1 ICache 32K 8-way L2 Cache 4M / 2 Cores ITLB 128 ent DTLB 256 ent Устройства 5 Integer 3 ALU + 2 AGU 2 Load/Store (1 Load + 1 Store) 4 FP (FADD + FMUL + FLOAD + FSTORE) 3 SSE (128 bit)

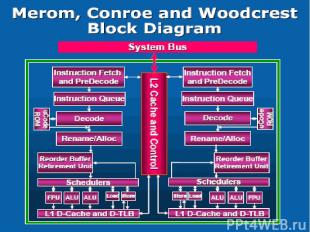
Intel Core AMD K8 L1 кэш данных 32 Кбайта 64 Кбайта L1 кэш инструкций 32 Кбайта 64 Кбайта Латентность кеша L1 3 цикла 3 цикла Ассоциативность L1 кеша 8-way 2-way Размер L1 TLB Инструкции – 128 вхождений Инструкции – 32 вхождения Данные – 256 вхождений Данные – 32 вхождения Размер L2 кэша 4 Мбайта на два ядра 1 Мбайт на каждое ядро Латентность кэша L2 14 циклов 12 циклов Ассоциативность L2 кэша 16-way 16-way Ширина шины L2 кэша 256 бит 128 бит Размер L2 TLB - 512 вхождений Длина конвейера 14 стадий 12 стадий Число x86 декодеров 1 сложный и 3 простых 3 сложных Целочисленные исполнительные устройства 3 ALU + 2 AGU 3 ALU + 3AGU Load/Store устройства 2 (1 Load + 1 Store) 2 FP ИУ FADD + FMUL + FLOAD + FSTORE FADD + FMUL + FSTORE SSE ИУ 3 (128-битные) 3 (64-битные)
")
Itanium 2 (Montecito)

Niagara

Особенности Niagara 8 ядер 4 потока на ядро Общий FPU 79 Ватт при 1.2 ГГц 26.5 ГБ/сек

Cell

Архитектура Cell

Cell Главный процессорный элемент Упорядоченное исполнение Поддержка работы с двумя потоками 8 синергетических процессорных элементов Ядро на основе 286 архитектуры Поддержка векторных вычислений 128 бит Отсутствие КЭШей Локальная память 256 Кбайт с прямым доступом Шина ввода вывода Пропускная способность 76,8 Гбайт/с

Шина взаимосвязанных элементов Передает 96 байт/цикл Более 100 уникальных запросов

Power Processor Element Два 64-битных ядра на основе архитектуры POWER Упорядоченное исполнение комманд Поддержка SMT (многопоточность) КЭШ 1го уровня: 32+32 Кбайт 2го уровня: 512 Кбайт

Synergistic Processor Element 4 целочисленных векторных устройства 4 векторных устройства с плавающей запятой 128 регистров по 128 бит 256 Кбайт локальной памяти Динамическая защита доступа к памяти
 256 GFLOPS с плавающей запятой 256 GOPS целоч")
Производительность Cell (для 4GHz) 256 GFLOPS с плавающей запятой 256 GOPS целочисленная арифметика 25 GFLOPS с плавающей запятой двойной точности











